
3 Tips for Evaluating your Codes Quality
One of the biggest impediments to delivering embedded software in a timely manner is the codes structural quality. Code quality in a project often starts okay but quickly deteriorates as teams rush to implement features as promptly as possible. Take, for example, two teams:
- Team A focuses on implementing features quickly with little focus on structural code quality
- Team B focuses on structural quality with less emphasis on quick delivery.
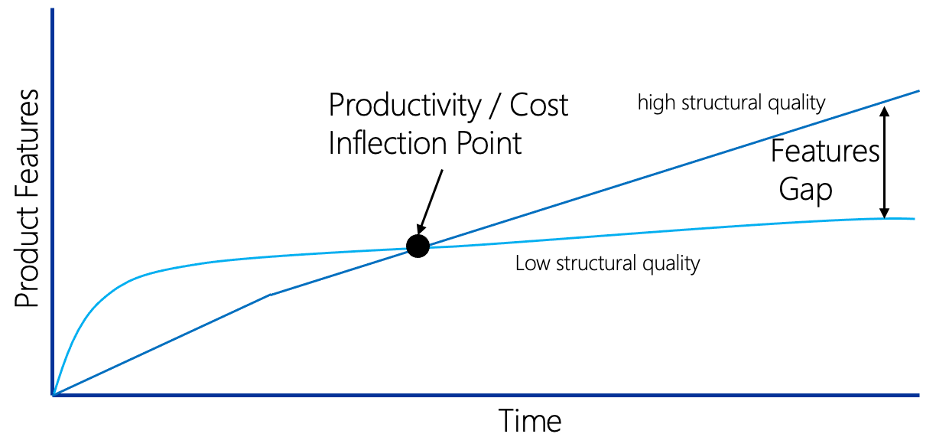
The number of features delivered over time might look something like the figure below:
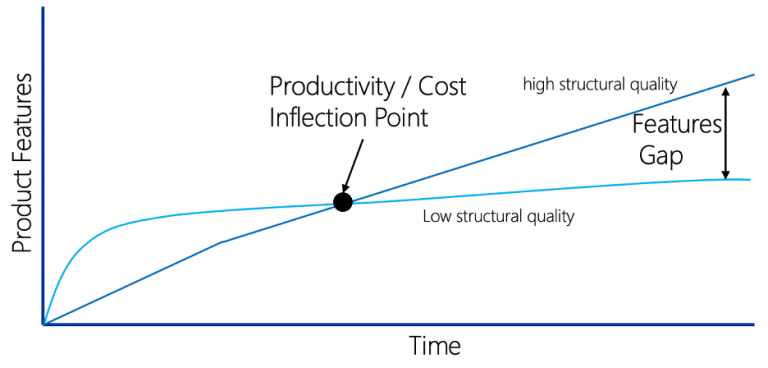
At the start of the project, Team A appears to be the heroes. They quickly implement and deliver features, outpacing Team B. Unfortunately, Team A’s low structural code quality quickly gets in the way of them delivering additional features. Each new feature starts to take more time and herculean efforts to implement. As a result, team A stagnates as they become bogged down in massive debugging activities every time a new feature is added.
Team B, on the other hand, while appearing to start slow, makes steady progress. Over time, they spend less time debugging and fighting with their code structure. They eventually reach a point where productivity and cost inflection compared to Team A. Team B continues forward, creating new features, which results in a feature gap between the two teams.
You want your team to perform like Team B, not Team A. Evaluating your code quality can and should be done throughout your development process. Here are three tips for evaluating your embedded software code quality.
Tip #1 – Analyze your software dependencies
A feature of high structural code quality is high cohesion and low coupling software. Cohesion refers to the degree to which the elements inside a module belong together. High cohesion means that everything in the module supports the function that the module serves in the software and nothing more. For example, a USART module is not also going to support CRC. While a CRC might be used on serial data passed to the USART peripheral, calculating the CRC does not belong in the USART module.
Coupling is the degree of interdependence between software modules; a measure of the closely connected two modules. The higher the coupling between modules, the greater the dependence. In software with high structural quality, the software modules have a minimal number of dependencies. Low coupling is an indicator of high structural quality. The tighter modules are coupled, the more a change in one module will affect another. If a team is not careful, their software structure can turn into a “big ball of mud”.
The Big Ball of Mud
A big ball of mud is easy to identify by performing a dependency analysis on the software. An example big ball of mud can be seen below:
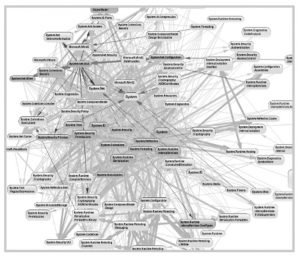
Notice that modules have dependencies that sprawl throughout the entire architecture. If you were to pick a module and try to update it or reuse it, a nightmare would ensue. It would be nearly impossible. Attempting to add new features to software like this is possible but often time-consuming and costly.
Analyzing Dependencies
Embedded software teams should analyze their software architecture and dependencies as they develop their software. If they do so, they can identify potential coupling issues early and resolve them before they evolve into a problem. For example, I had a project I was working on where I wrote a task that controls a pump. As I wrote the code, I analyzed its dependencies which you can see below:
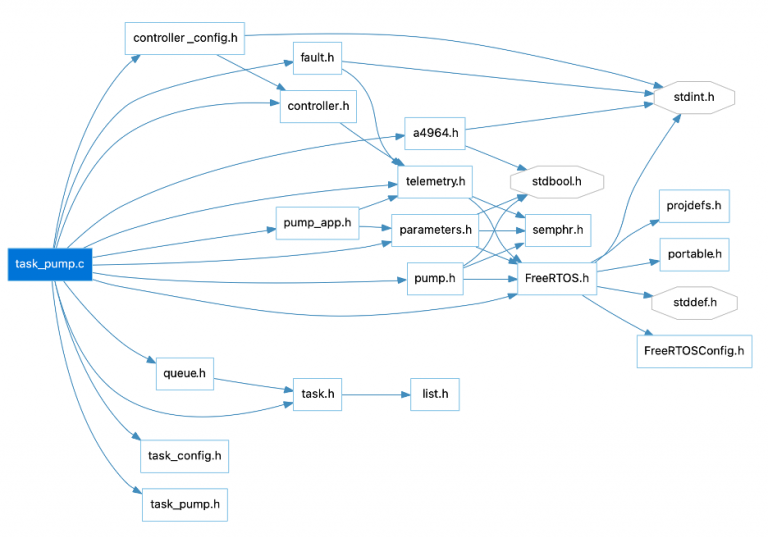
In general, the dependencies are pretty good for an embedded system. Notice that the flow of the dependencies from left to the right is nice and linear. We don’t see cross-coupling in the dependencies, and the flow is nice and clean. We also don’t see any cyclical dependencies either. However, you can see that towards the middle/right; the operating system might cause dependency issues. In general, we wouldn’t want our software to depend on the RTOS, but several modules appear to have an RTOS dependency. Upon identifying this, an abstraction layer can be added to better manage the dependency.
Tip #2 – Measure function length
A simple technique that can be used to estimate code quality is to measure the length of each function in your code base. Large functions have a statistically higher probability that they contain bugs. In many instances, a long function indicates that the function is not adhering to the Single Responsibility Principle (SRP)! Each function should do just one thing and be responsible for doing just one thing. (Note: This principle is often applied at the class or module level, but in C, it can be applied at the function level as well).
Large functions often do too much, indicating an underlying issue with the code quality. Analyzing the code can point to potential problems. For example, in the graphs below, you can see the largest functions and files in an example code base. The most significant function in the code has over 5,000 lines of code (LOC)! On the flip side, there is a module with nearly 18,000 LOC!
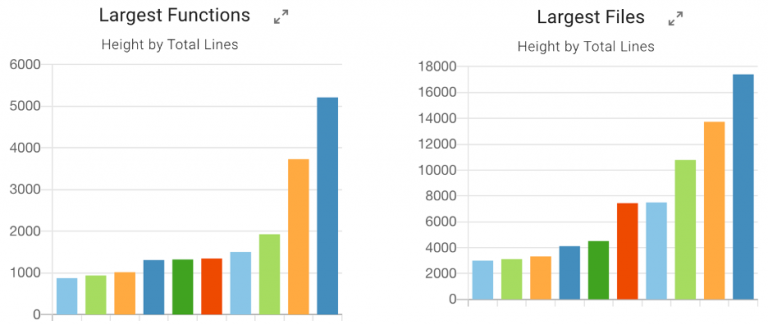
The LOC per function metric can identify modules where issues may live when analyzing a code base. When such code is identified, they are high-priority functions, files, and modules to refactor and break up into more meaningful units. For example, a 5,000-line function could likely be broken up into 50 helper functions that are clearer and more maintainable. Unfortunately, large functions like that are often nearly impossible to test!
Tip #3 – Every Code Unit should have Tests
Tests, particularly unit tests, are critical to ensuring that your code is high quality. A test verifies that the function meets the requirements for what the function is supposed to do. If you do not have tests for your functions, then you have no way to verify that the function does what it is supposed to! In addition, when code changes, there is no way to know whether you broke anything unless there are tests to verify the function is still behaving as expected.
Tests can be the greatest indicator of the code’s structural quality. This is because developers are often forced to manage dependencies, minimize coupling, abstract their interfaces, and perform many other best practices when writing unit tests. As a result, code that has low structural quality is often difficult to test. Conversely, code that has high structural quality is easy to test.
When I review code for quality, one of the first things I do is examine the tests or lack thereof. A trick can be used to determine if you have enough tests for your software. Cyclomatic Complexity tells a developer the number of linearly independent paths through a function. Developers can use tools like pmccabe to measure every function in their code. Then, sum up the total, which will tell you the minimum number of test cases you should have to test your code.
I had a customer who had written a piece of software with which they were having many problems. They had gone a year late delivering and had spent far more on the product than they anticipated. The first step in the redesign was for me to review what was there, the quality and if there was anything that could be salvaged. A quick analysis revealed that they need ~9,000 tests to verify their function behavior. They had none. It explained why they were so late, over budget, and stuck with a giant ball of mud.
Evaluating Code Quality Conclusions
Structural code quality can be linked to whether a team can deliver its software on time and within budget. High structural code quality will result in consistent feature deliveries. Achieving high structural code quality is not something that just happens. Teams must set up the processes and procedures to evaluate and monitor their software. Quality issues are easier to handle as they occur rather than waiting until the end of a project when the easiest thing to do is just start over. (Which usually results in the same problems all over again).
In today’s post, we explored three low-hanging tips for how to measure the quality of your code. These tips include:
- Measuring dependencies
- Keep functions small
- Every code unit should have tests
If you start with these, you’ll be on your way to understanding the defects and potential issues in your embedded software. Once you can see and understand, only then can you develop your action plan to improve your software structure quality.
Need Assistance?
If you know you have quality and embedded software development issues, you don’t have to go it alone. Contact me at [email protected], and we can discuss how best to get you and your team back on track to delivering high-quality embedded software.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.

How best do you handle lower level code that is communicating with hardware? Do you have unit tests with HW in the loop? Or do you stub those out for the unit tests?
Thanks for the question.
How to best handle it will depend on your end goals. Personally, I like to use the Mock capability within the test harness to build and test the interface to the hardware device. James Grennings TDD book has a great example of how to do this for an ST Microelectronics flash chip. In addition, I’ll usually write unit tests designed to be ran on hardware as part of HIL testing.
“I had a customer who had written a piece of software with which they were having many problems. They had gone a year late delivering and had spent far more on the product than they anticipated. ”
I see this all the time, the root cause that I have always found is that the customer did not have a clear, and written design document, (or design goals if you prefer) from the start.
Great tips about dependencies and lines of code per function. What tools did you use to create the illustrations in your article?
I used a combination of Understand from SciTools, and Doxygen GraphViz. Several others can be used to do this work, but I didn’t use them in the article.
Thanks for the question!