
5 Tips for Versioning Embedded Software
As you know, embedded software changes at a dramatic rate. How we manage software version information dramatically affects whether we can successfully understand the differences between those versions. Several years ago, I wrote a blog entitled 5 Tips for Versioning Embedded Systems. Today’s post will explore a few tips for versioning embedded software.
Tip #1 – Use a standard Git process
Over the years, I’ve seen just about every version control process ranging from the hope and pray your computer doesn’t crash method to clearly defined Git processes. Before developing a successful versioning scheme, it’s essential to follow a robust Git process. For example, recently, I’ve come across several companies that only work out of their Master branch, which was causing a lot of problems with multiple developers. A standard process can help alleviate issues and improve visibility in the repository.
A Git process that I’ve found to be simple, robust, and easy to implement is the process written about in A Successful Git Branching Model written by Vincent Driessen. The overall process can be seen in Figure 1 (and I highly recommend reviewing the blog post). There are undoubtedly other processes, but I’ve found this one the simplest and easiest to get buy-in.
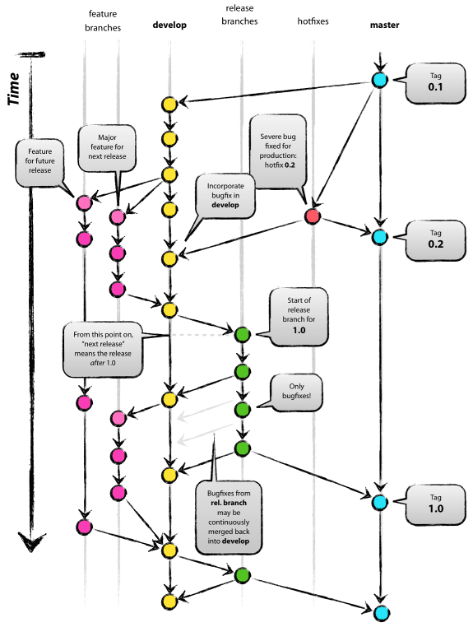
Figure 1 – A Successful Git Branching Model demonstrates how to manage various branches, including feature, develop, releases, hotfixes, and master. (Image Source)
Tip #2 – Only version release branches
In the “old days,” every time a software module was updated, a new version number would be assigned to the code. Changing the version number was meant to indicate that the software had changed. However, for many teams, versioning software every time a change has been made doesn’t make sense. The time between software changes is dramatically getting shorter and shorter. It’s not uncommon to commit new code a dozen times or more per hour.
The best place to version software is in the release branch of the Git repository. While features are in development, it doesn’t make sense to increment the version number continuously! Instead, features should be fully developed and fleshed out before being added to a release of the software. This gives developers the freedom to focus on rapid feature development without worrying about how they are going to version their software. It’s only versioned when the team is ready to release a new version or a hotfix.
Tip #3 – Don’t add version and date info to individual modules
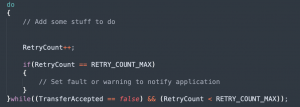
Diligently tracking the changes made to software has always been important to developers. Early in my career, it was drilled into me how important this was and that this information should be tracked down to the individual function! It was not uncommon to find comment blocks in my code that looked the following:
/*************** MODULE REVISION LOG *
* Date Version Author Description
* 09/01/15 0.5.0 Jacob Beningo Interface Created.
* 11/10/15 1.0.0 Jacob Beningo Interface released.
****************************************************/
Or at the function level like:
/***************************************************
* Function : Dio_Init()
- * – HISTORY OF CHANGES –
* Date Software Version Initials Change
* 09/01/2015 0.5.0 JWB Interface Created
* 11/10/2015 1.0.0 JWB Added const to parameters
*****************************************************************************/
While the code looks nicely documented, I’ve found that this versioning has several problems. First, module and function level versioning is difficult to synchronize with the overall application versioning. So, the version numbers often don’t match or correlate properly. Second, versioning at this level can confuse developers. Third, putting versioning information all over the place makes it hard to find what changed and when. Finally, due to other reasons, I found this version information rarely gets updated, making it a waste of space and providing essentially no value to the code base.
Tip #4 – Add version history comments to the README
The most logical place to store version history information is not at the module or function level but in the README file. When I get a new code base, one of the first places I go is a README. If the version information is there, it’s one of the first things I look at to get a feel for what has recently changed and how the software evolved.
Another place where version information can be stored is in a version.h or version.c module. There are several reasons why I am not the biggest fan of putting changelogs here. First, version.h often contains autogenerated version information that is used by the application. We don’t want our log information to be a file that can be overwritten or where we must overly complicate a script to preserve our comments. Second, storing the information in version.c, while convenient, is creating a source module that has no actual code in it.
Tip #5 – Use a script to update your software version
There are three types of version updates that are typically applied to a codebase:
- Major version release
- Minor version release
- Hotfix version release
It’s okay to manually update these releases because we are typically manually branching to the release branch anyways; However, I have found that this process can be simplified and less error-prone if a script is used instead.
Several things can be done with a versioning script. First, you can update the version of your code by having the script automatically update and generate a file like version.h. Second, you can even automate the branching and tagging process in your Git repository. Finally, you can write a script that combines it all.
Conclusions
Embedded software versioning isn’t rocket science, but to do it effectively, you need to take a few moments to define your process. As discussed in Tip #1, using a repository process can help you manage your software quickly, whether you have 1 or 1,000 developers. Once you have this process down, versioning is as simple as using a script to set your version and then managing your releases and tags appropriately.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.



Agree with #3, we have this meaningless rule in source code in our coding standards. The simplest thing is to increment the version automatically using environment variable BUILD_NUMBER from Jenkins on the master brauch. It avoids forgetting to update it manually, which leads to the confusion of builds with different functionality but the same version numbers. For the readme, we simply save a PDF of the Jenkins log, which has all commits for that build and again, information cannot be missed.
Perfect! Thanks for the comment!
As a long-time single developer I have kept my versioning system to be a simple as possible no matter how many code files/modules I have. I preceed Git by a decade or two so I am sticking to it 😉
-Version history with descriptions in the main file only.
-Global const version string below version block for inclusion in data exports or visible in GUI if available.
-Changes in code files commented with only the new version number
-Version is locked only when sent outside of the company.
K.I.S.S !
These days I use Github actions to built the code. With the help of mathieudutour/github-tag-action it finds the latest tagged version and increments this for the current build. Once all tests have passed it tags the code and uploads the binary as a Github release.
To keep the number of releases at bay it only does this on the master branch. The pipeline does allow for branch builds as well in which case the version number is set to 0.0.0. As part of the version info the first 10 characters of the githash are shown with the version number, which makes it easy to link the binary code to the source that was used to build it.