
Firmware Error Handling using Do while Loops
An interesting area of a code base to examine is error handling. I’ve found that many firmware and embedded software projects don’t do an excellent job managing errors and faults. For example, there is a lot of optimism that if I want to transmit a character over a serial interface, the character will be transmitted 100%, no matter the circumstances. While optimism in a lab setting is expected, for production code, developers should ask themselves what can go wrong and how they should handle errors and faults. This post will explore the types of firmware error handling I often see in open source and production code and how we can create better error handling using do while loops.
Typical Firmware Error Handling
The type of error handling I often encounter can’t be considered error handling at all. In fact, error handling is nearly non-exist, and if something goes wrong, the system will end up in bad shape. For example, if you were to examine the start-up code in your microcontroller vendor’s support package, you would likely find some code that starts up the microcontroller’s internal and/or external oscillator. The code usually looks something like the following:
[snippet slug=2022-09-29-snippet1 lang=c_cpp]
Do you see any problems with the error handling of this code? I can spot several right off the bat. The biggest issue I see is that if the initialization fails, we end up in an infinite loop that prevents the system from booting!
Let’s look at another example. What if I want to transmit characters over a serial interface like SPI. It’s pretty common to come across code that looks like the following:
[snippet slug=2022-09-29-snippet2 lang=c_cpp]
The code above checks the return value from the transmit function, which is good, but if the transfer fails, the code will get stuck in an infinite loop. So I’m not sure this is much better than other code I see, which just assumes that the transfer was successful, as shown below:
[snippet slug=2022-09-29-snippet3 lang=c_cpp]
Do while loop in c
One of the most underutilized loop statements in firmware and embedded software systems is the use of do while loops. The structure of a do while statement is quite simple:
[snippet slug=2022-09-29-snippet4 lang=c_cpp]
The significant difference between using a do while loop versus a while loop is that the statements within the do while block will execute at least once. The fact that the code runs at least once can help simplify error handling code. For example, if I want to use a while loop, I usually have to create extra variables and set their states before the loop, as shown below:
[snippet slug=2022-09-29-snippet5 lang=c_cpp]
The same code can be rewritten and simplified using a do while loop as shown below:
[snippet slug=2022-09-29-snippet6 lang=c_cpp]
The above code is a good step towards better firmware error handling, but we aren’t quite there yet. We are still plagued by the potential for infinite loops to occur.
A general pattern for error handling with do while loops
As embedded software developers, we must recognize that while the likelihood that a peripheral locks up or stops responding may be small, when we ship thousands of products for several years, the chances that it will happen in the field do become non-zero. Depending on the type of products you design, handling the fault correctly might be insignificant or result in significant lawsuits again your company.
There is a simple code pattern that I use whenever I am going to interface with hardware. The code pattern does several things:
- Runs the desired code to interact with the hardware at least once
- If the first run were unsuccessful, it would retry the interaction
- If a predetermined number of retries has been reached, the code will not hang but will set an error and move on.
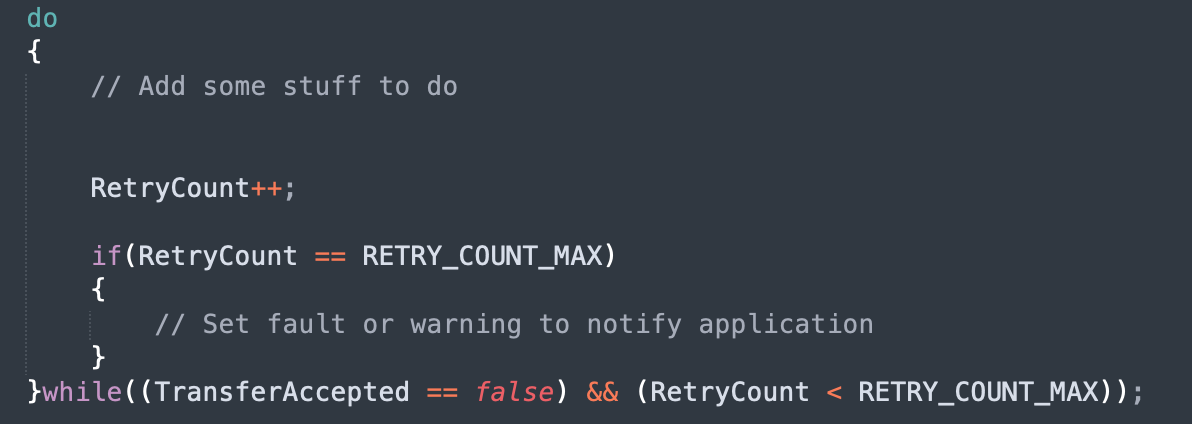
As you might suspect, a do while loop with some additional logic can help us to achieve the above requirements. The template for the implementation looks like the following code:
[snippet slug=2022-09-29-snippet7 lang=c_cpp]
The code is simple and compact and can easily be reused for any hardware-dependent or even hardware-independent application calls. If I were to write some code to interact with the SPI bus, I can take the template and with a few modifications end up with something like the following:
[snippet slug=2022-09-29-snippet8 lang=c_cpp]
Firmware Error Handling Conclusions
The state of error handling in the embedded software industry today is quite dire. We often assume that everything will work the way it’s supposed to. Unfortunately, that is not the case. We need to assume that interactions with hardware might fail. If they do, we may want to retry the exchange again before setting an error. In this post, we looked at how developers can use the do while loop to build some simple error handling logic that allows them to retry an interaction before setting an error.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.
What if transfer is accepted during last retry count?
Good catch! There should be an additional check in the conditional for whether it was successful or not. I’ve update the code snippet.
An alternative would be to move the fault checking outside the do/while loop, and then only check if TransferAccepted == false. Something like:
do { bool TransferAccepted = SERCOM4_SPI_WriteRead(&TxBuffer[Device][0], TxSize, &RxBuffer[Device][0], RxSize); RetryCount++; } while((TransferAccepted == false) && (RetryCount < RETRY_COUNT_MAX)); if(TransferAccepted == false) { Fault_Set(SPI_TRANSFER_FAILED); }Thanks for the comment!
Thank you for the clarification.
Good point of not waiting forever on hardware, especially during initialisation.
Not really related to the subject, I would like to comment on the (IMHO) silly and dangerous habit of comparing a Boolean result with “false” or “true”.
Why would you write things like “TransferAccepted != true”, “TransferAccepted == false”, or any other combination of “!=”/”==” and “false”/”true”?
“TransferAccepted” is already a Boolean, and if you compare it with true or false, you get…. a Boolean!. There is no point.
I think there are at least 2 reasons NOT to do that:
1. It is dangerous
2. It promotes bad naming of the Boolean variable
Ad 1:
If for whatever reason a Boolean variable gets a value that is neither the numerical value of false or true, checks like “== false” and “== true” both yield false. What a nasty surprise!
Ad 2:
“TransferAccepted” is a good variable name, because it is perfectly clear what the meaning is of TransferAccepted being true or false. Just write “while (!TransferAccepted)” and “if (TransferAccepted)”, etc. Only if you use a bad variable name like “Flag”, you have to resort to comparing that name with false or true.
Thanks for the comment! Good points!
Is it possible to preserve line breaks in the comment box?
I have to check with my web team. I’ve found that to be annoying as well.
One more thing:
“while((GCLK_REGS->GCLK_SYNCBUSY & GCLK_SYNCBUSY_GENCTRL_GCLK2) == GCLK_SYNCBUSY_GENCTRL_GCLK2)” can simplified as:
“while((GCLK_REGS->GCLK_SYNCBUSY & GCLK_SYNCBUSY_GENCTRL_GCLK2) != 0)”
Keep it simple, keep it DRY!
Thanks for the comment.
The code I used in the example was actually copied from the Microchip Harmony code for the ATSAM54E. So it’s a literal example of how microcontroller vendors provide code that developers are using in their production code!
If you were to perform branch coverage tests and you have to execute the branch where “RetryCount == RETRY_COUNT_MAX” is true and “TransferAccepted == true” how would you proceeding?
Would you perform sophisticated mocking of the function “SERCOM4_SPI_WriteRead” to return “true” after a define number of retry?
Thanks for the question.
Thanks for the question.
There are a few ways you could do it. First, you could create a mock that for the maximum or error case expects the call to be done RETRY_COUNT_MAX times. Alternatively, you could create a test double that behaves as needed.
In order to avoid having to build multiple test functionalities into a single function, you could create test double functions like SercomNormalTestWriteRead, SercomMaximumTestWriteRead, SercomErrorTestWriteRead and then instead of using the SERCOM4_SPI_WriteRead, we could use a function pointer and update the pointer to point at the test double we want to execute.
Thanks for your response.
Also, what do you think about having a while loop waiting on essential peripheral in a boot software?
What i mean is, for example, the case where you need to access a NVRAM that is not responding in the boot and that access is mandatory for the application execution. In the case where you have a watchdog, is it not valid to just retry in a while loop until the watchdog reset the board? A error flag would not be much of a help in that case i think.
It depends on the product and what’s acceptable for a failure. What happens if the NVRAM has failed permanently? Should the device just sit in a reset loop forever without the user ever knowing what is wrong? Or should it try to initialize the NVRAM and after X failures, move on and boot into a “safe mode” or “limp mode”?
Those types of decisions really depend on the product.
Good question!
I see, thank you!
Hi Jacob, great article.
I was recently reading an article over on the memfault blog (https://interrupt.memfault.com/blog/firmware-watchdog-best-practices#a-basic-implementation) and they are advocating that adding timeouts can cause more problems than they fix?
They say: “Adding timeout logic and attempting to gracefully recover is something that should be done sparingly. When this is done, you open yourself to more complex recovery paths that may have problems of their own. Additionally, important state about the underlying issue is lost making root cause analysis even harder. Failing out exactly where the hang is taking place makes it easier to root cause and fix the actual problem.”
Wondering your opinion? Should we fail immediately or attempt to recover?
Thanks for the question.
Like with most things engineering, we need to be careful about generalizing. (Unfortunately I generalize quite a bit).
It depends on the situation. For the customers and work that memfault does, yes, that advice is probably a best practice. For many IoT devices, I agree that you are probably better off just failing and letting the watchdog recover.
When I am working with my customers writing flight software for spacecraft, drones, and other aircraft, we don’t have the luxury of just failing and debugging later. If something does not respond, we often need to try to automate and attempt recovery. If that fails, then the issue is raised higher. It does increase complexity, which is why its good to avoid if you can.
I totally disagree with this article.
Why would we continue to run with faulty SPI/xtal/hw?
Getting stuck + WDT = safe mode is the correct way.
Also just use for loop and break out on first success, waaay easier to read.
Thanks for the comment.
You have to keep in mind that there is not a single solution that can be applied across all application. For example, what if there is a non-critical sensor that has stopped responding in a safety critical device like a ventilator. Are you going to let it hang up and reset? What if the device is a propulsion system and it’s in the middle of a critical trajectory maneuver? What if the communication issue is due to temporary environmental noise?
Letting a WDT catch a problem is not always the safe and correct way to manage a bus with a fault. It’s application dependent and this is one example of a safe recovery mechanism that doesn’t blow up the system and force a restart.