
Improving Code Integrity with a Stack Guard
Developing reliable embedded software comes down to planning for the worst-case scenario and ensuring that there are guards and traps in place to handle these situations. One area of neglect in embedded software is often the stack. The stack is temporary storage that is used by the microcontroller to store information such as local variables, return addresses from a function call, interrupt context and function arguments.
Setting the stack size for a given application is totally up to the developer. Many compilers will provide a default value of 0x400 bytes but is this really enough for all applications? Determining the size that the stack should be for any given application is difficult. The developer needs to determine the worst-case usage, which includes understanding the maximum function call depth, how many local variables will be defined on the stack and even how many concurrent interrupt contexts that might need to be stored. This is not an easy feat even with today’s technologies and tools.
What is it then that a developer does? He simply determines the direction in which the wind is blowing that day, pulls a number from thin air and puts that number as the size of the stack. The bottom line is what is the worst thing that can happen if the stack overflows the memory region to which it was assigned? Figure 1 shows a typical memory map and the locations of where the heap, stack and global/static regions are arranged. As the stack grows it will grow towards the global / static variables region of the memory map. If the stack were to overflow it would begin to overwrite the global and static variables definitions! Causing values stored in memory to become corrupted and have the opportunity to wreak havoc on the behavior of the system.
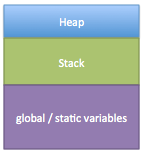 Figure 1 – Memory Map
Figure 1 – Memory Map
A reliable system can’t allow the stack to overflow. So what techniques are available to detect when such as situation arises? One of the most common techniques is to create a guard region between the stack and the global / static variable regions. This guard region should be chosen to be of sufficient size so that if the stack were to overflow it wouldn’t be able to penetrate the memory region below. Some common values are 16 and 32 bytes but these needs to be based on the largest object that can be placed on the stack at a time. An example of the memory map setup can be found in Figure 2.
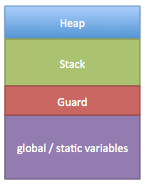 Figure 2 – Stack Guard Memory Map
Figure 2 – Stack Guard Memory Map
There are two ways in which the guard area can be monitored by the microcontroller. The first is to use an onboard memory protection unit (MPU) if it is available on the microcontroller. In this case the MPU would be setup to fire an interrupt if there are any write accesses to the stack guard region of memory. The interrupt firing would indicate that the stack has overflown and protective measures along with error logging can take place.
In the event that an MPU is not available, the guard region of memory can be filled with a known bit pattern during system initialization. A task or function can then be created that periodically checks the guard region and compares it to the known bit pattern. If the pattern has changed then the application can force an interrupt that then logs the error and begins corrective action.
There are two different methods that can be used to create the big pattern. The first is to use the linker file to create a FILL region in the stack guard. This region will then automatically be initialized during the C copy down at start-up. The second method would be to manually write the bit pattern as part of the system initialization by creating a pointer to the start of the stack guard and then placing the bit pattern into memory.
It can be argued that having a stack guard in place will decrease the efficiency of the embedded software. Having the application periodically check that the guard is still in tact can require a function call, a loop and dereferencing a pointer. This performance hit is hardly noticeable on a modern microcontroller and should be a mute point. When creating a reliable system these types of checks need to be put into place in order to ensure that the system is operating as expected. In the event of a catastrophic failure such as a stack overrun, the system will be able to detect the overrun and take corrective actions before something terrible happens to the system or even worse a user of the system.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.
