
A Simple, Scalable RTOS Initialization Design Pattern
I often find that developers initialize task code in seemingly random places throughout their application. This can make it difficult to make changes to the tasks, but more importantly just difficult to understand what all is happening in the application. It also makes it so that the application is not very scalable or easy to adapt and sometimes results in developers not knowing that a task even exists! There is a simple, scalable RTOS initialization design pattern that I use that resolves all these issues.
The design pattern, which I often follow for as much of my code as possible, is to create a generic initialization function that can loop through a configuration table and initialize all the tasks. Let’s examine how we can create such a design pattern.
Step #1 – Create a Task Initialization Structure
The first step is to examine the task create function for your RTOS and see what parameters are required to initialize a task. This often varies slightly but it usually includes things like:
- Pointer to the task function
- Size of the stack
- Passed parameter pointer
- Task priority
- Task handle pointer
- MPU table pointer
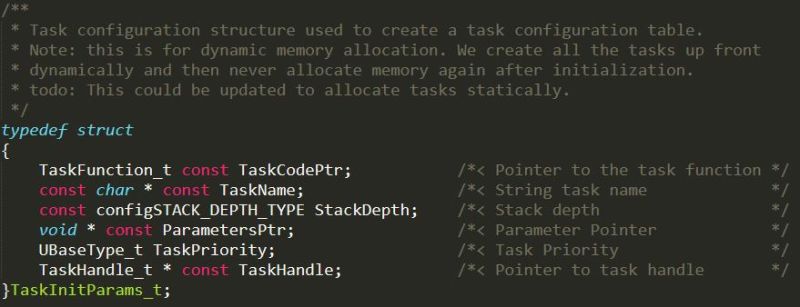
A task initialization structure is just a structure that contains all the parameters required to initialize the task. As I mentioned earlier, this is slightly different between RTOS’s, but an example structure can be seen below for FreeRTOS.
[snippet slug=rtos_init_snippet_1 lang=c_cpp]
Note that we typedef the structure with the name TaskInitParams_t.
Step #2 – Create a Task Configuration Table
Once we have our TaskInitParam_t created, we can create a configuration table that contains all our tasks and the parameters required to initialize them. This is nothing more than creating an array of TaskInitParam_t. Each element in the array contains all the information that we defined in TaskInitParams_t that will then be used to initialize a task. For example, an embedded system may contain a task initialization table that looks like the following:
[snippet slug=rtos_init_snippet_2 lang=c_cpp]
You’ll notice that there are a lot of parameters in this table that we have not defined. These are all parameters that we would define in our application for initialising the task. For example, TASK_TELEMETRY_PRIORITY would be defined with many of the other values in a task configuration module.
Step #3 – Create an Initialization Loop
Once the configuration table is created, all that is needed to initialize the tasks is a for loop that loops through the table and then calls the task creation function. Each loop through, we access the structure data and pass it as a parameter to the function. For example, we could initialize the tasks in this example using the following loop:
[snippet slug=rtos_init_snippet_3 lang=c_cpp]
Note that we place (void) in front of xTaskCreate to show that we are ignoring the return value of xTaskCreate. Generally we want to check the return value for a function, but in this case we would create all our tasks during initialization and would not expect to have any memory issues. (Not a good assumption). However, we could rely on the FreeRTOS malloc failed hook to catch any dynamic memory allocation issues during development. Alternatively, we could check the return value and then create a function that checks and recovers if there is an issue. It’s really up to the developer.
Conclusions
This simple RTOS initialization pattern that we’ve just examined is scalable, reusable, and super simple to modify for your purposes. It’s a great example for how developers can leverage configuration-based design. The pattern can be used with any RTOS, but we used the FreeRTOS APIs as an example. Making a change to the task is nothing more than adding or removing an entry in the TaskInitParameters array.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.

Hi,
this idea can also be extended to peripherals initialization.
I.e. one need to put peripherals registers addresses+values into an array and then loop over it.
Some time ago I saw such a pattern in polish electronics magazine “Elektronika Praktyczna”.
It also clearly summarizes how the peripherals are initialized, in one common place.
However, whenever feasible, I prefer to keep the peripherals’ initialization together with the driver code.
But for simpler applications, this array-based approach might prove cleaner and being easier understood.
Cheers! 🙂
—
Best regards,
Andrzej Telszewski
Absolutely! I actually use this approach for peripheral intitialization when I am writing the driver myself. Generally I separate the table and the driver so that the table is in a config file and then passed as a pointer to the peripheral init function.
Thanks for the comment (and technique extrapolation!)
You could validate the return code with an assert during debugging, e.g.
for (…)
{
xReturned = xTaskCreate(…)
assert (xReturned == pdPASS)
}
I would prefer to play it safe, and have the parameter table defined as “TaskInitParams_t const TaskInitParameters[TASKS_TO_CREATE] = ”
and later use “TaskCount <TASKS_TO_CREATE" in the init loop.
And, of course, check the return values, knowing that everything that can't go wrong will go wrong sometimes..
Hi
This looks interesting . I don’t understand the following …..”You’ll notice that there are a lot of parameters in this table that we have not defined. These are all parameters that we would define in our application for initialising the task. For example, TASK_TELEMETRY_PRIORITY would be defined with many of the other values in a task configuration module…….. You refer to something called a “task configuration module ” What is this ? Is this just assignments of values to the task variables ? Do you have example code showing how this works ?
The configuration module is nothing more than a header file with the definitions for the configuration settings. For example, you might have a task_config.h module. In it, you’d have definitions like:
#define TASK_TELEMETRY_STACK_DEPTH (2048U)
#define TASK_TXMESSAGING_STACK_DEPTH (1024U)
That’s all this is. Then, instead of worrying about modifying a source module, the header file just needs to be updated.