Reproducible Builds: The Missing Foundation for Embedded CI/CD
Embedded CI/CD has become table stakes in modern firmware development. In fact, Embedded CI/CD and DevOps in general were one of the main themes at Embedded World 2025.
Every conference talk, every tooling vendor, every blog post will tell you to automate your builds, test continuously, and deploy faster. For cloud-native teams working with homogeneous environments, that advice works. But for embedded teams, it falls apart quickly.
Reproducible builds aren’t the only foundation; they sit alongside a clear architectural framework and disciplined development process — covered together in my book on Embedded Software Design.
The gap between Embedded CI/CD as it’s preached and Embedded CI/CD as it’s practiced is wider than most people admit: hardware dependencies, proprietary toolchains, long certification cycles, and products that need to be maintained for a decade or more. For the embedded systems industry, these are the norm rather than edge cases, and they introduce unique problems that generic DevOps advice doesn’t account for.
“Generic” CI/CD advice prioritizes speed over consistency. For embedded systems, the missing piece isn’t more automation. It’s reproducibility. If you can’t reliably reproduce a build of the same binary, from the same source, with the same toolchain, months or years later, then your Embedded CI/CD pipeline is built on sand. You can’t debug a field failure. You wouldn’t be able to pass a certification audit. You can’t even maintain a product with any confidence.

In this post, we’ll break down what actually changes when you bring CI/CD into embedded development, why reproducibility has to come first, the two failure modes that quietly destroy build reproducibility, how containerization solves both, and the four stages that turn a reproducible build into a fully automated Embedded CI/CD pipeline.
“Regular” DevOps CI/CD vs. Embedded CI/CD
The CI/CD playbook that works for web applications will actively mislead embedded teams. Cloud-native CI/CD assumes you can spin up identical environments on demand, deploy continuously, roll back in minutes, and test entirely in software. Embedded development doesn’t operate that way.
Builds usually target specific hardware architectures through cross-compilation toolchains. Testing often requires physical hardware or cycle-accurate simulation. Deployment means flashing firmware onto devices that may be in the field, in a factory, or even in orbit. And you can’t “roll back” firmware on a medical device or automotive ECU the way you roll back a web service. (For a deeper look at what an embedded pipeline actually has to do, see essential tools for embedded CI/CD.)
Certification changes the equation further. In regulated industries (e.g., automotive, medical, industrial), every build artifact needs to be traceable. The binary that passed functional safety testing must be the exact binary that ships. The toolchain that produced it must be documented and qualified. The entire chain from source code to deployed firmware needs to be auditable, sometimes years after the product launched. These aren’t minor workflow differences, because they change what Embedded CI/CD even means in practice.

Reproducibility as the Foundation
In regulated embedded development, if you can’t reproduce the exact binary, you can’t certify it. And if you can’t certify it, you can’t ship it. Reproducibility means that the same source code, processed by the same toolchain, in the same environment, produces an identical binary output. Every time, on any machine. This sounds straightforward, but in practice, achieving it requires deliberate effort that many teams skip until it’s too late.
Consider what happens without it: a customer reports a critical firmware defect on a product that shipped eighteen months ago. To debug it, you need to recreate the exact binary that’s running in the field. If you can’t, you’re debugging a different binary, and any fix you produce may not behave the same way on the original hardware and firmware combination. (And if you think pinning your source code in a GitHub release is enough, it isn’t. The same codebase can produce different binaries when the toolchain underneath it changes.)
The same problem surfaces during certification audits. Standards like ISO 26262, IEC 61508, and IEC 62304 require demonstrable traceability from source code to binary. Auditors will ask you to rebuild firmware and show that the result matches what was originally certified. If your build environment has shifted since the original release (even slightly), that match can fail.
Embedded products routinely have lifecycles of ten to fifteen years. Reproducibility isn’t really a convenience. Reproducibility becomes an operational requirement that determines whether you can maintain, update, and recertify products across their full lifespan.
Why Builds Break: Toolchain Drift and Environments Rot
If reproducibility is the goal, it’s worth understanding exactly how builds become unreproducible in the first place. Two forces are consistently responsible.
Reason #1: Your Toolchain Can Drift If It Isn’t Version-Locked
A compiler update you didn’t plan for can change the binary you didn’t expect. Toolchain versions get updated across developer machines, sometimes intentionally, sometimes as a side effect of system updates. A minor compiler patch changes optimization behavior, or a linker update shifts memory layout. The build compiles without errors, but the resulting binary is different. And in safety-critical systems, a different binary is a different certification artifact.
Even within the same compiler family, minor version differences can produce subtly different code generation. In embedded, those subtle differences can mean a timing-sensitive interrupt handler behaves differently in the field than it did on the test bench. This kind of drift is difficult to detect and expensive to diagnose in retrospect.
Reason #2: Your Environment Can (and Will) Rot
The build machine that works today won’t exist in three years. Build environments accumulate undocumented dependencies over time: OS patches, shared library updates, PATH configurations, environment variables. All of these influence the build output but rarely get tracked explicitly. Reconstructing what’s actually pinned and where often starts with searching the codebase itself. A fast, regex-capable search tool like AstroGrep can surface every place a toolchain version, environment variable, or build flag is referenced in minutes rather than hours. When the build server hardware fails, or a team member who configured it leaves, or you need to recreate a build from two years ago, the environment is effectively gone.
This problem compounds with product lifecycle. Embedded products routinely ship and then require maintenance for ten to fifteen years. The operating system your build server ran in 2020 may not be available (or even installable) in 2030. If your build environment isn’t captured as a portable, versioned artifact, you’re accumulating technical debt that only surfaces at the worst moment: during a field recall, a certification renewal, or a customer escalation that requires an exact binary match.

Containers as the Reproducibility Layer
Containerization solves both problems by turning the build environment itself into a versioned, portable artifact. A Docker container packages the entire build environment (OS, toolchain, dependencies, and configuration) into a single image that runs identically on a developer’s laptop, a CI runner, or a cloud-hosted build server. When the container image is tagged and stored alongside the source code, the build environment becomes as reproducible as the code itself. (If Docker is new to your team, start with this introduction to Docker for embedded software developers.)
This shifts the documentation problem, too. Instead of maintaining a wiki page describing how to set up a build machine (a page that’s almost always incomplete or outdated), teams now maintain a Dockerfile that is the build environment. If you can pull the container, you can build the firmware. No tribal knowledge required.
For embedded teams working across multiple architectures, containers also eliminate the need to manage separate physical build machines for each target. A single CI pipeline can run Arm, RISC-V, and Renesas builds from different containers, all orchestrated by the same automation layer.
IAR Build Tools, tailored for Embedded CI/CD, are designed for exactly this workflow. The toolchain runs from the command line inside Docker containers on both Linux and Windows, integrates directly with CI/CD orchestrators like Jenkins, GitHub Actions, and GitLab, and provides pre-built container images that eliminate the setup overhead. So instead of spending weeks configuring a custom build environment, teams can pull a validated container and have a reproducible, automated build pipeline the same day.
For teams in regulated industries, the toolchain’s TÜV SÜD certification for ISO 26262, IEC 61508, and IEC 62304 means the containerized environment also carries the functional safety qualification, which is reproducibility and compliance in the same artifact.
From Reproducible Builds to an Automated Embedded CI/CD Pipeline
Once the build environment is containerized and reproducible, the path to a fully automated Embedded CI/CD pipeline becomes much more practical. Here’s what that progression typically looks like.
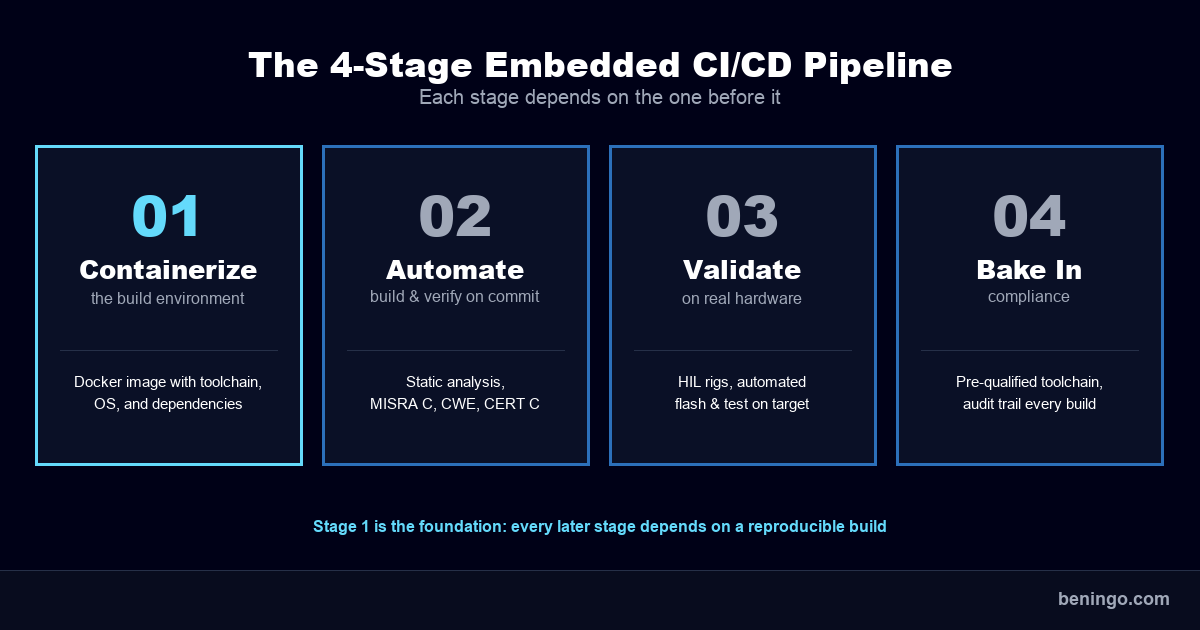
Stage 1: Containerize the Build Environment
Package your toolchain, dependencies, and build configuration into a versioned Docker container. Tag the container image alongside your source releases. This is the foundation, and every subsequent stage depends on this being solid. If the build isn’t reproducible, automating it only means you’re reproducing problems faster.
Stage 2: Automate Build-and-Verify on Every Commit
Wire the containerized build into your CI system so that every commit triggers a build, and every build includes automated verification. This is where static analysis becomes part of the daily workflow rather than a pre-release afterthought. Tools like IAR’s C-STAT, for code quality and compliance, can run MISRA C/C++ checks, CWE, and CERT C compliance scans on every commit.
Runtime analysis tools like C-RUN add another layer, detecting stack overflows, memory leaks, and bounds errors during automated test execution.
Stage 3: Integrate Hardware-in-the-Loop Validation
Simulation and off-target testing cover a lot of ground, but some behavior can only be validated on real hardware. Hardware-in-the-loop (HIL) rigs connected to your Embedded CI/CD pipeline can run regression tests on physical targets automatically. The containerized build ensures the binary running on hardware is identical to what was verified earlier in the pipeline. Debuggers like C-SPY can be driven from the command line, enabling automated flash, execution, and result collection.
No more uncertainty about whether the test binary matches the release binary.
Stage 4: Bake Compliance into the Pipeline
For safety-critical products, compliance shouldn’t be a gate that happens at the end of development. It should be woven into every stage of the pipeline. Pre-certified toolchains eliminate one of the biggest certification headaches: qualifying the tool itself. Automated compliance reports generated with every build create an audit trail that’s always current, rather than a documentation scramble before each release milestone.
Scaling Embedded CI/CD Without Overengineering
Adopting Embedded CI/CD doesn’t require a dedicated DevOps team or a six-month infrastructure project. But there are two common mistakes that turn a practical improvement into an expensive distraction.
Mistake #1: Building Your Own Toolchain Infrastructure from Scratch
You don’t need a custom DevOps platform to get reproducible builds. Many embedded teams assume that adopting CI/CD means constructing a bespoke infrastructure: hand-built Docker images, homegrown build scripts, and a dedicated engineer to maintain the whole stack. For most teams, that is overengineering. It delays adoption by months and creates a maintenance burden that competes directly with product development.
The more practical path is to start with pre-built, validated container images from your toolchain vendor. IAR provides ready-to-use Docker containers with their Build Tools, along with public automation recipes and a cookbook for customizing them to specific project needs. Instead of spending weeks assembling a build environment, teams can pull a container and have a working pipeline running the same day.
Mistake #2: Ignoring Licensing Constraints in Dynamic CI Environments
Traditional licensing models break the moment you try to scale your pipeline. Node-locked licenses, licenses that are tied to a specific machine, are fundamentally incompatible with containerized CI/CD. Containers are ephemeral. CI runners spin up and tear down on demand. If your toolchain license is tied to a MAC address or hostname, your Embedded CI/CD pipeline can’t scale beyond a single build machine. That bottleneck defeats the entire purpose of automation.
Capacity-based licensing, like the model IAR uses for their platform, is designed for this scenario. License tokens are shared across containers, CI runners, and cloud instances, allowing teams to scale builds dynamically. This is an easy detail to overlook during initial adoption, but it becomes a hard blocker the moment you try to parallelize builds, move to cloud-hosted runners, or onboard additional developers to the pipeline.
Fix Your Foundation Before You Automate
Embedded CI/CD isn’t really about speed. It’s about confidence: confidence that the binary you shipped is the binary you certified, and confidence that the firmware running in the field can be rebuilt, debugged, and patched five or ten years from now. You don’t get that confidence from automation alone. You get it from reproducibility. Automation just lets you scale it.
If you’re looking at your current build process and wondering where to begin, here are three steps you can take this week:
- Audit your build environment. Pick a release from twelve to eighteen months ago and try to rebuild it. Document everything that’s missing, broken, or different. That gap is your reproducibility debt, and it’s worth knowing how big it is before you plan the work.
- Version-lock your toolchain. Pin your compiler, linker, and build tool versions in your repo. Not in a wiki page, not in tribal knowledge, in the repo itself alongside the source. If you can’t tell me what compiler version produced your last release without checking Slack, this is where the work starts.
- Containerize one project. Pick a single, smaller project and move its build into a Docker container. Tag the image, store it alongside the source, and prove to yourself that any team member can pull the container and produce the same binary. Once you’ve done it once, the pattern scales.
You don’t have to build any of this from scratch. IAR already publishes pre-built Docker containers for their Build Tools, along with example automation recipes and a cookbook for adapting them to your project. If you want a working starting point instead of a six-week infrastructure project, that’s a reasonable place to look.
Their Build Tools are also pre-qualified for ISO 26262, IEC 61508, and IEC 62304, which means the containerized environment carries the functional safety certification with it. For regulated work, that’s one less thing you have to qualify yourself. If you want to see what a containerized embedded build pipeline actually looks like, the IAR platform demo is a good next stop.
Want embedded engineering insights like this delivered to your inbox? Sign up for my Embedded Bytes newsletter to get the latest posts, insights, and hands-on tips delivered straight to your inbox.
Struggling to keep your development skills up to date or facing outdated processes that slow down your team, raise costs, and impact product quality?
Here are 4 ways I can help you:
- Embedded Software Academy: Enhance your skills, streamline your processes, and elevate your architecture. Join my academy for on-demand, hands-on workshops and cutting-edge development resources designed to transform your career and keep you ahead of the curve.
- Consulting Services: Get personalized, expert guidance to streamline your development processes, boost efficiency, and achieve your project goals faster. Partner with us to unlock your team's full potential and drive innovation, ensuring your projects success.
- Team Training and Development: Empower your team with the latest best practices in embedded software. Our expert-led training sessions will equip your team with the skills and knowledge to excel, innovate, and drive your projects to success.
- Customized Design Solutions: Get design and development assistance to enhance efficiency, ensure robust testing, and streamline your development pipeline, driving your projects success.
Take action today to upgrade your skills, optimize your team, and achieve success.